Why Graph Databases Are The Future

We are living in the era of big data, caused by the increase in the amount of information we are generating and collecting, thanks to the arrival of the internet. We need to store and analyze this big amount of data in the most efficient way possible. This is why graph databases come in place. If you need to analyze big databases, I will referrer to big databases of sets of 10 megabytes or higher you have to use graph databases. Graph databases are an intuitive way to represent your data and also given this graph representation you are able to apply the knowledge of graph theory into databases.
In any standard databases such as MySQL or SQLite, your data is stored tables, keys, relationships, queries, select , joins, etc, but there are limitations in terms of ways that we can query the data and how we can represent this data. In a regular relational database you can’t do for example a shortest path. Standard databases worked very well in the early days of business computing, where information volumes grew slowly. For more complicated operations, however — such as establishing a relationship between data points stored in many different tables — the necessary operations quickly become complex, slow and cumbersome. On the other hand, graph databases allow you to have a more natural representation for your data.
Big companies today use graph database technology for :
- Fraud detection
- Real-time recommendation engines
- Master data management (MDM)
- Network and IT operations
- Identity and access management (IAM)
Below I show you Google searches from 2004 to 2017 for SQL and Neo4j. As you can see the Google Trend data shows that SQL searches are decreasing through the year. On the other hand, searches of Neo4j are increasing in popularity over the years.
Some of the disadvantages of relational databases are:
- Relational database management systems suffer at scale.
• Query response times become very slow as the number of tables grow and queries involving multiple JOIN operations.
• Difficult to represent complex domain application data in a relational model.
Below you can see a running time comparison for a SQL JOIN query versus graph traversal on a data set of a large size.
If you want to understand what are graph databases and how they work, you have to be a little bit familiar with graph theory but for simplicity I will describe a graph as a connection between two points called nodes and the connection can be called relationship. As I said graph is composed of two elements: a node and a relationship.
Each node represents an entity (a person, place, thing, category or other piece of data), and each relationship represents how two nodes are associated. For example, the two nodes cake and dessert would have the relationship is a type of pointing from cake to dessert.
Consider another example: Twitter is a perfect example of a graph database connecting 330 million monthly active users.
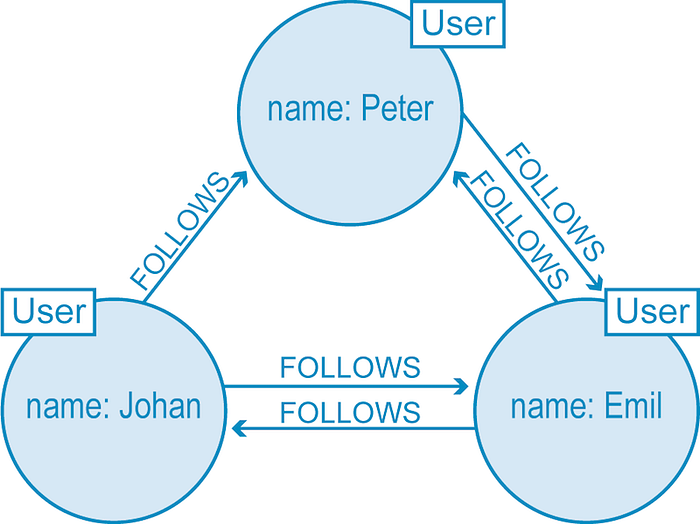
In the illustration above, we have a small slice of Twitter users represented in a graph database. Each node (labeled User) belongs to a single person and is connected with relationships describing how each user is connected. As we see below, Peter and Emil follow each other, as do Emil and Johan, but although Johan follows Peter, Peter hasn’t (yet) reciprocated.
The graph paradigm goes well beyond databases and application development; it’s a reimagining of what’s possible around the idea of connections. And just like any new problem-solving framework, approaching a challenge from a different dimension often produces an orders-of-magnitude change in possible solutions.
Neo4j is one of the most useful graph databases. Neo4j is an open-source, NoSQL, native graph database that provides an ACID-compliant transactional backend for your applications. Neo4j is a graph database designed to treat the relationships between data as equally important to the data itself. It is intended to hold data without constricting it to a pre-defined model. The data is stored in a graph that shows how each node connects with or is related to others.
Cypher is an expressive and concise graph database query language for the Neo4j graph database. It is important to note that there are other query languages for graph type databases, such as SPARQL, which can be used on data represented in an RDF model.In Cypher, we are able to query to find data that matches a specific pattern.The following is a simple graph pattern, which is represented in Cypher as:
(emil)<-[:KNOWS]-(jim)-[:KNOWS]->(ian)-[:KNOWS]->(emil)
In conclusion, graph databases are more common that most people think. The real world is very interconnected, and graph databases aim to mimic those sometimes-consistent, sometimes-erratic relationships in an intuitive way. That’s what makes the graph paradigm different than other database models, it maps more realistically to how the human brain maps and processes the world around it.
Sources:
